Speech segmentation is the determiation of the begninning and ending boundaries of acoustic units. It is an important subproblem of speech recognition and often overlaps with other domain problems such voice activity detection (VAD), end point detection, text segmentation etc. Generally, segmentation is devided to two levels:
- Lexical segmentation: decomposition of spoken language into smaller lexical segments (e.g. paragraphs, sentences, phrases, words, syllables)
- Phonemic segmentation: breaking and classification of the sound signal at the lowest level to a string of acoustic elements (phones) which represent a distinct target configurations of the speech tract (regarding articulation as well as form of excitation)
Research in AIIA is done regarding context-free automatic segmentation. By discounting linguistic contraints (context, grammar, semantic information) it is possible develop or assist multilingual applications, concatenative speech synthesis systems, speaker segmentation, speech trascription in computer-aided systems etc.
Conventional speech detection and segmentation systems that follow energy-based approaches work relatively well only in high signal to noise ratios (SNR) and for known stationary noise, so they are inefficient in real-world recordings where speakers tend to leave artefacts such as breathing/sighing, mouth clicks, teeth chatters, and echoes. Statistical methods are more efficient but there issues when working with small sample sizes.
| Energy methods | Statistical methods | |
|---|---|---|
| Implementation | Rely on energy thresholds and heuristics to identify acoustic changes |
Speech and noise statistics. Use a decision rule. |
| Requirements | Fast, computationally efficient. Online - real time processing. |
Slow, computationally intensive. Offline applications. |
| Performance | Misclassify non-stationary noise as speech activity, can not identify unvoiced speech segments like fricatives satisfactorily |
Good precision even in low SNRs, robust in non-stationary noise. |
Our Method
A novel automatic acoustic change detection algorithm based on Bayesian statistics has been developed in AIIA. Common statistical methodology in speech segmentation, embraces binary decision-making strategies. Under certain assumptions, t is a change point if the window Z=X+Y is better modelled with a single distribtution instead of two separate for its sub-windows X and Y.
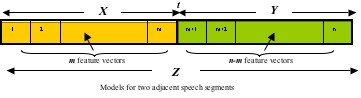
We model speech samples with a two-sided generasized Gamma distribution (GΓD). Using a computationally inexpensive maximum likelihood (ML) approach, we employ the Bayesian Information Criterion (BIC) for identifying the phoneme boundaries in noisy speech.

The method is based on DISTBIC (Delacourt & Wellekens, 2000). This is an offline multi-pass algorithm that first uses a distance measure (e.g. Kullback Leibler distance KL, Generalised Likelihood Ratio GLR, etc.) to identify candidate change points, then employs BIC between adjacent windows dynamically determined by the candidate points of the first step.

Instead of Gaussian distribution (GD), we model adjacent signal segments with GΓD which offers better representation power for both speech and silence/noise. Also we explore different criteria such as BICC and ABF2 which are more efficient for small sample sizes.

Early experiments in M2VTS and TIMIT speech corpora give evidence that using ABF2 instead of BIC and modelling the signal with GΓD instead of GD yields better segmentation accuracy.
| Overall system evaluation using the F1 measure for the M2VTS dataset | Overall system evaluation using the F1 measure for the TIMIT dataset |
|---|---|
 |
 |
Relevant Publications
G. Almpanidis and C. Kotropoulos, "Voice activity detection using the generalized Gamma distribution", in Proc. 4th Panhellenic Artificial Intelligence Conf. (SETN-06), Heraklion, Greece, May 19-20, 2006.
G. Almpanidis and C. Kotropoulos, "Voice activity detection with generalized Gamma distribution", in Proc. 2006 IEEE Int. Conf. on Multimedia and Expo (ICME 2006), Toronto Ontario, Canada, 9-12 July, 2006.
G. Almpanidis and C. Kotropoulos, "Phoneme segment boundary detection based on the generalized Gamma distribution", in Proc. 2006 Int. Symposium on Industrial Electronics (ISIE 2006), Montreal, Canada, 9-13 July, 2006.
Research Projects
Herakleitos - (Operational programme for Education and Initial Vocational Training - 3rd Community Support Framework): Processing of Multimedia Signals
Speaker segmentation aims at finding the speaker change points in an audio stream. It is a prerequisite for audio indexing, speaker identification\ verification\ tracking, automatic transcription, and dialogue detection in movies. A popular method for speaker segmentation is metric-based segmentation, which focuses on segmenting the input audio stream by evaluating its distance from different segmentation models.
Our Method
Our lab is utilizing the Bayesian Information Criterion (BIC) for speaker segmentation.
Two different systems have been developed.
- The first is a multiple-pass method which uses a fusion scheme
- The second employs auxiliary second order statistics and T2 Hotelling statistic
A third system is currently under development.

Downloads
A demo file can be found here.
Relevant Publications
M. Kotti, E. Benetos and C. Kotropoulos, "Automatic Speaker Change Detection with the Bayesian Information Criterion using MPEG-7 Features and a Fusion Scheme", in Proc. of IEEE International Symposium Circuits & Systems(ISCAS 06), 21-24 May, Island of Kos, Greece.
M. Kotti, E. Benetos, C. Kotropoulos and L. G. Martins, "Speaker Change Detection using BIC: A comparison on two datasets", in Proc. of International Symposium Communications, Control and Signal Processing, 2006.
M. Kotti, L. Gustavo, P. M. Martins, E. Benetos, J. S. Cardoso and C. Kotropoulos, "Automatic speaker segmentation using multiple features and distance measures: a comparison of three approaches", in Proc. of the IEEE International Conference on Multimedia and Expo (ICME 2006), Toronto, Ontario, Canada, 9-12 July, 2006.
Research Projects
MUSCLE - “Multimedia Understanding through Semantics, Computation and LEarning” (FP6-507752)
VISNET - European Network of Excellence, funded under the European Commission IST FP6 programme
Automatic musical instrument classification is the first step in developing applications for:
- Automatic music transcription
- Effective data organization and search
- Multimedia databases annotation
Our Method
A Sound Description Toolbox for automatic feature extraction from audio files has been developed. Features covered are:
- Sound description features used in general audio data (GAD) classification experiments
- Spectral descriptors defined by the MPEG-7 audio standard are covered
A multitude of classifiers has been developed:
- A novel supervised classifier based on non-negative matrix factorization (NMF) techniques

- Multilayer perceptrons (MLPs)
- Radial basis functions (RBF) networks
- Support vector machines (SVMs)
Downloads
-
Relevant Publications
E. Benetos, M. Kotti, C. Kotropoulos, J. J. Burred, G. Eisenberg, M. Haller, and T. Sikora, "Comparison of subspace analysis-based and statistical model-based algorithms for musical instrument classification", in Proc. 2nd Workshop On Immersive Communication And Broadcast Systems, October 2005.
E. Benetos, M. Kotti, and C. Kotropoulos, "Applying supervised classifiers based on non-negative matrix factorization to musical instrument classification", in Proc. IEEE Int. Conf. Multimedia & Expo (ICME 2006), Toronto, Ontario, Canada, 9-12 July, 2006.
E. Benetos, C. Kotropoulos, T. Lidy, and A. Rauber, "Testing supervised classifiers based on non-negative matrix factorization to musical instrument classification", in Proc. 14th European Signal Processing Conf., September 2006.
Research Projects
Pythagoras II - "Efficient techniques for information organization, browsing, and retrieval in multimedia'', funded by the Greek Ministry of Education and the European Union
MUSCLE - “Multimedia Understanding through Semantics, Computation and LEarning” (FP6-507752)
Speech is different between persons and it also depends on the emotional state of the speaker. The primitive emotional states are anger, happiness, neutral, sadness, and surprise. The task of emotional clustering refers to uniquely assigning emotional feature vectors into the emotional states.
Our Methods
A) Two well-known variants of the self-organizing map (SOM) that are based on order statistics are the marginal median SOM (MMSOM) and the vector median SOM (VMSOM). We employ the MMSOM and the VMSOM to re-distribute emotional speech patterns from the Danish Emotional Speech database that were originally classified as being neutral to four emotional states such as hot anger, happiness, sadness, and surprise. The latter experiment is motivated by the following facts:
- There are emotional facial expression databases such as the Action-Unit coded Cohn-Kanade database, where the neutral emotional class is not represented adequately. Accordingly, facial expression feature vectors are not clustered to the neutral emotional class.
- For the emotional speech databases, the utterances are regularly classified as neutral. Accordingly, when the neutral class is not represented in one modality it is difficult to develop multimodal emotion recognition algorithms.
- Frequently, the ground truth information related to emotions that is provided by the human evaluators is biased towards the neutral class.
It was proven that the marginal median SOM and the vector median SOM perform better than the standard SOM.
B) Another important issue arises when the emotional feature vectors are represented as points on the (N - 1)-dimensional simplex and the elements of these patterns are the posterior class probabilities for N classes. Such patterns form N clusters on the (N - 1)-dimensional simplex. The challenge is to reduce the number of clusters to N - 1, in order to redistribute the features classified into a particular class in the N - 1 simplex, according to the maximum a posteriori probability principle in an optimal manner using a SOM. We have accomplished a mathematical derivation of the training algorithm for a SOM that reduces the number of clusters by one on a simplex subspace.
Downloads
-
Relevant Publications
V. Moschou, D. Ververidis, and C. Kotropoulos, "On the Variants of the Self-Organizing Map That Are Based on Order Statistics ", in Proc. 2006 Int. Conf. Artificial Neural Networks, Athens, Sep. 2006.
C. Kotropoulos and V. Moschou, “Self Organizing Maps for Reducing the Number of Clusters by One on Simplex Subspaces“, in Proc. 2006 IEEE Int. Conf. Acoustics, Speech, and Signal Processing, vol. 5, pp. 725-728, May 2006.
Research Projects
MUSCLE - “Multimedia Understanding through Semantics, Computation and LEarning” (FP6-507752)
Pythagoras II - Funded by the Hellenic Ministry of Education in the framework of the program

Affect recognition aims at automatically identifying the emotional or physical state of a human being from his or her face and voice. The emotional and physical states of a speaker are known as emotional aspects of speech and are included in the so-called paralinguistic aspects. Although the emotional state does not alter the linguistic content, it is an important factor in human communication, because it provides feedback information in many applications.
Affect Recognition is related to the following tasks:
- Data collection procedures, the kind of speech (natural, simulated, or elicited), the content, and other physiological signals that may accompany the emotional speech.
- Short-term features (i.e. features that are extracted on speech frame basis) that are related to the emotional content of speech. The emotions affect the contour characteristics, such as statistics and trends.
- Emotion classification techniques that exploit timing information and other techniques that ignore time context.
Our Method
- A data collection is under construction. Subjects are a) kids while trying to imitate an actor, b) kids imerged in a VR enviroment. Two cameras, a professional condense microphone, a sweat sensor, and a heart beat sensor were used.
- Two databases are obtained, namely: a) Danish Emotional Speech (DES), and b) Speech under simulated and Actual Stress (SUSAS).
- Feature extraction algorithms were developed: a) fundamental frequency (pitch), b) formants from reflection coefficients of the linear prediction model, and c) cepstral coefficients.
- Feature selection algorithms are improved, namely the Sequential Floating Forward Selection algorithm is improved by statistical comparisons between feature sets using confidence intervals of the prediction error achieved by a feature set.
- Several classifiers are developed a) Bayes classifier using mixtures of Gaussian densities (GMM), b) Support vector machines, c) Bayes classifier by using Parzen windows, d) neural networks (self organizing maps), e) the Brunswik model for emotion perception is under development.

Downloads
-
Relevant Publications
D. Ververidis and C. Kotropoulos "Fast Sequential Floating Forward Selection applied to emotional speech features estimated on DES and SUSAS data collections", in Proc. of European Signal Processing Conf. (EUSIPCO 2006), Florence, Italy, 4-8 September, 2006.
M. Haindl, P. Somol, D. Ververidis and C. Kotropoulos, "Feature Selection Based on Mutual Correlation", in Proc. 11th Iberoamerican Congress on Pattern Recognition (CIAPR) , Mexico, 2006.
V. Moschou, D. Ververidis, and C. Kotropoulos, "On the Variants of the Self-Organizing Map That Are Based on Order Statistics ", in Proc. 2006 Int. Conf. Artificial Neural Networks, Athens, Sep. 2006.
D. Ververidis and C. Kotropoulos, "Emotional speech classification using gaussian mixture models and the sequential floating forward selection algorithm", in Proc. of 2005 IEEE Int. Conf. on Multimedia and Expo (ICME 2005), Amsterdam, 6-8 July, 2005.
D. Ververidis and C. Kotropoulos, "Emotional speech classification using Gaussian mixture models", in Proc. of2005 IEEE Int. Symposium Circuits and Systems (ISCAS 2005), pp. 2871-2874, Kobe, Japan, May, 2005.
D. Ververidis, C. Kotropoulos and I. Pitas, "Automatic emotional speech classification", in Proc. of ICASSP 2004, vol. I, pp. 593-596, Montreal, Montreal, Canada, May, 2004.
D. Ververidis and C. Kotropoulos "Automatic Speech Classification to five emotional states based on gender information", in Proc. of 12th European Signal Processing Conf. (EUSIPCO '04), pp. 341-344, Vienna, Austria, September, 2004.
D. Ververidis and C. Kotropoulos, "A Review of Emotional Speech Databases", in Proc. of 9th Panhellenic Conf. on Informatics (PCI `03) , pp. 560-574, Thessaloniki, Greece, 21-23 November, 2003.
D. Ververidis and C. Kotropoulos, "A State of the Art Review on Emotional Speech Databases", in Proc. of 1st Richmedia Conf., pp. 109-119, Laussane, Switzerland, October, 2003.
D. Ververidis and C. Kotropoulos, "Emotional Speech Recognition: Resources, features and methods", Elsevier Speech communication, vol. 48, no. 9, pp. 1162-1181, September, 2006.
I. Kotsia, and I. Pitas, "Facial Expression Recognition in Image Sequences using Geometric Deformation Features and Support Vector Machines", IEEE Transactions on Image Processing, December, 2006.
Research Projects
PENED 2003 - “Use of Virtual Reality for training pupils to deal with earthquakes” (01ED312)
MUSCLE - “Multimedia Understanding through Semantics, Computation and LEarning” (FP6-507752)
Speech processing has proved to be an excellent tool for voice disorder detection. Among the most interesting recent works are those concerned with Parkinson's Disease (PD), multiple sclerosis (MS) and other diseases which belong to a class of neuro-degenerative diseases that affect patients speech, motor, and cognitive capabilities. Such studies are based on the special characteristics of speech of persons who exhibit disorders on voice and/or speech. They aim at either evaluating the performance of special treatments (i.e. Lee Silverman Voice Treatment [LSVT] ) or developing accessibility in communication services for all persons. Thus, it would possibly be a matter of great significance to develop systems able to classify the incoming voice samples into normal or pathological ones before other procedures are further applied.
Our Method
We have developed detection algorithms (classifiers) for two voice pathologies:
- vocal fold paralysis (male speakers)
- vocal fold edema (female speakers)
They are associated with communication deficits that affect the perceptual characteristics of pitch, loudness, quality, intonation, voice-voiceless contrast etc, having similar symptoms with PD and other neuro-degenerative diseases. The main causes of vocal fold paralysis are usually either several surgical iatrogenic injuries or a glitch in the recurrent laryngeal nerve or possibly a lung cancer, while malfunction at the vocal folds due to edema is usually caused by more trivial reasons such as mild laryngeal injuries, common infectious diseases that affect the respiratory system, or allergies in drugs.
In particular, we have assessed the performance of
- Fisher's linear classifier
- K-nearest neighbor classifier
- nearest mean classifier
- linear sample-based parametric classifier
- dual-space linear discriminant analysis-based classifier
using a multitude of frame-based features or utterance-averaged frame-based features, such as
- 14-order linear prediction coefficients (LPCs) extracted on frame-basis (every 20msec) that reduced by Principal Component Analysis
- Mel-Frequency Cepstral Coefficients (MFCCs) + Delta + Delta-Delta
- Perceptual Linear Prediction (PLPs) coefficients
- RASTA coefficients
- Minimum Variance Distortion-less Response (MVDR) spectrum coefficient
on the database of disordered speech recorded by Voice and Speech Lab of Massachusetts Eye and Ear Infirmary (MEEI) [sustained vowel “Ah” /a/].
|
|
|
(a) |
(b) |
|
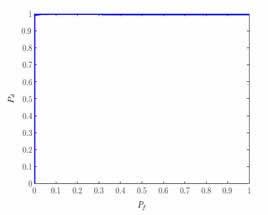
| Receiver operating characteristic curves using a linear sample-based parametric classifier fed with frame-based PLPs for: (a) vocal fold edema detection (b) vocal fold paralysis detection |
||
|
|
|
(a) |
(b) |
|
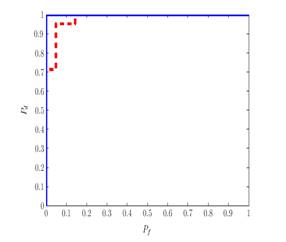
| Receiver operating characteristic curves using a linear sample-based parametric classifier for vocal fold paralysis detection (a) when it is fed with frame-based MFCCs (blue curve) and frame-based LPCs (red curve) and (b) when it is fed with utterance-averaged MFCCs (blue curve) and utterance-averaged LPCs (red curve) |
||


Downloads
-
Relevant Publications
M. Marinaki, C. Kotropoulos, I. Pitas and N. Maglaveras, "Automatic detection of vocal fold paralysis and edema", in Proc. of 8th Int. Conf. Spoken Language Processing (INTERSPEECH 2004), Jeju, Korea, October, 2004.
E. Ziogas and C. Kotropoulos, "Detection of vocal fold paralysis and edema using linear discriminant classifiers", in Proc. of 4th Panhellenic Artificial Intelligence Conf. (SETN-06), vol. LNAI 3966, pp. 454-464, Heraklion, Greece, May 19-20, 2006.
Research Projects
MUSCLE - “Multimedia Understanding through Semantics, Computation and LEarning” (FP6-507752)