Information Retrieval (IR) in the Web requires us to consider both content and linking. A well-known application of Web IR is a web search engine. The heart of a web search engine is the web crawler - a software agent that traverses the hypertext structure of the Web automatically, starting from an initial hyper-document or a set of starting points (seeds) and recursively retrieving all documents referenced by that document. The visiting strategy of the crawler characterises the purpose of the search engine. Contrary to large-scale, generalized engines (Google, Teoma, etc.) which try to index all the Web, vertical search engines only cater for topical resource discovery and they offer better precision.
| Generalized Engines | Specialized Engines | |
|---|---|---|
| Examples | Google, Teoma. | Krugle, Simply Hired. |
| Purpose | General purpose. Try to cover all the Web. | Targeted, focused, topical. Index a small portion of the Web. |
| Requirements | Large scale. Vast requirements in storage, resources. | Small scale. Need "smart" retrieval and management. |
| Maintain | Full update is difficult. Freshness? | Easy to update. Small index. |
| Quality | Good recall. Bad precision. Noise. | Good precision. Bad recall. |
| Visiting Strategy | BReadth First Search (BRFS). | BeSt First Search (BSFS). |
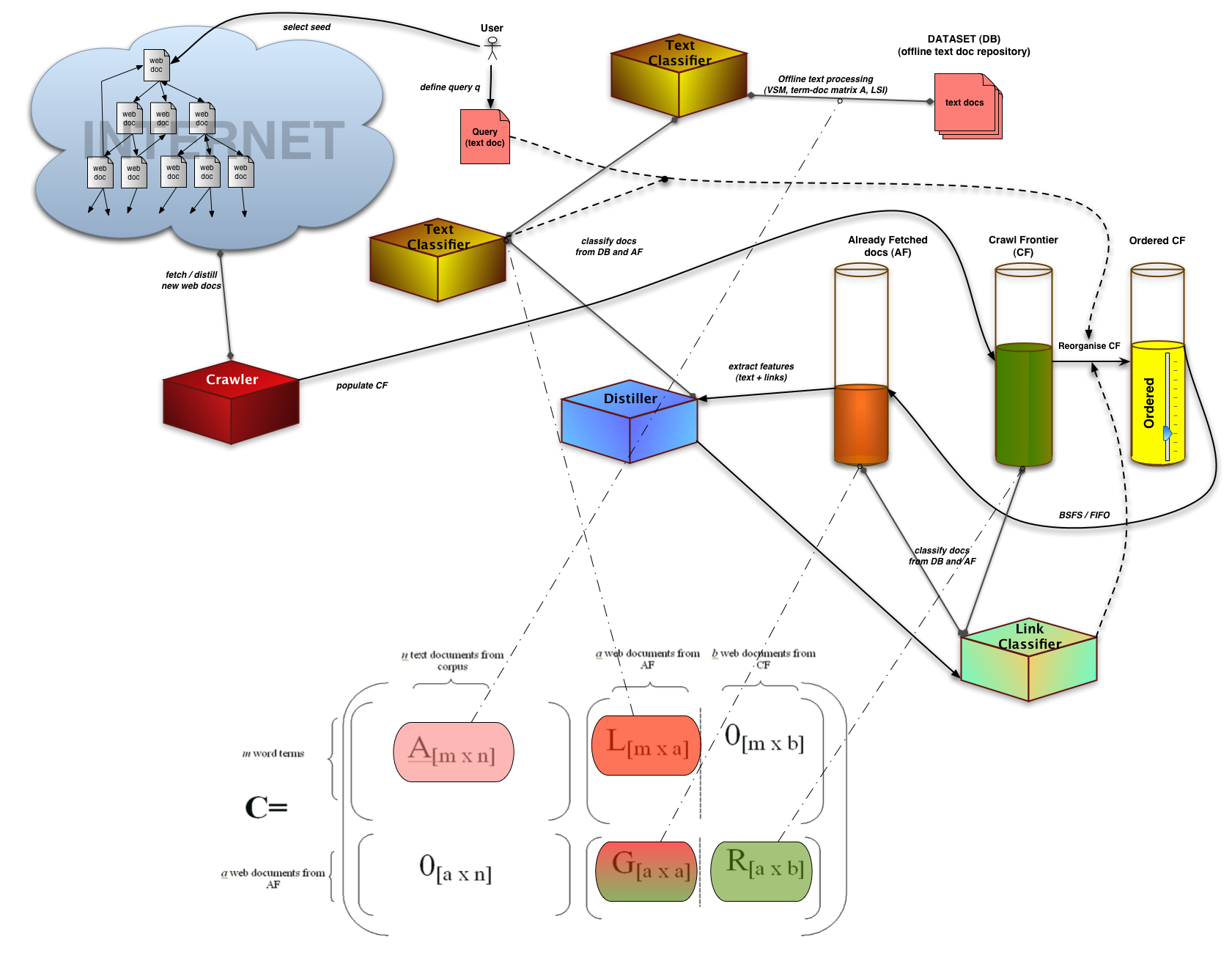
Vertical search engines typically employ a focused or topic-driven crawler, that analyses its crawl boundary in order to find the links that are likely to be most relevant for the crawl while avoiding irrelevant regions of the Web. A focused crawler maintains two queues of URLs:
- One containing the already visited links (AF)
-
and another having the references of the first queue which is called Crawl Frontier (CF)
The challenging task is ordering the links in the Crawl Frontier efficiently. The importance metrics for the crawling can be either interest driven where the classifier for document similarity checks the text content and popularity/location driven where the importance of a page depends on the hyperlink structure of the crawled document.
Topical web IR has various issues:
- How is it possible to select the most promising canditate links from the CF when these have not been parsed/distilled yet? We do not have information from their text content and we only have partial hyperlink information. We know some of their ancestors (from AF) but none of their children (outlinks).
- How do we consider a document in CF as "good"? Do relevant documents point to relevant links?
-
Is it possible to use previous (historic) knowledge (e.g. either text or link information from a previous crawl) to assist the crawling procedure?
- etc
Our Method (Hyper Content Latent Analysis HCLA)
We have developed a novel Latent Semantic Indexing (LSI)- based classifier that combines link- and text- analysis in order to retrieve and index domain specific web documents. We assert that it is easier to build an offline text document dataset than an offline web graph since this way we avoid data freshness issues. Furhermore, the vetical search engine's topic can be easily expressed using a text query (a few keywords).
In our method, HCLA, we extend the usual "bag-of-words" vector space model representation by considering both word terms and links for document relevance. In the new space (expanded term-document matrix C), each web document is represented by both the terms it contains and its hyperlinks - it is the concatenation of its terms and its outlinks. Text documents (and queries) are similariy expanded. This permits us to rank candidates in CF using full information from AF and text information from an offline text corpus against the user's text query input using LSI. SVD-updating is used as an inexpensive method of handling newly inserted documents. The CF reordering procedure occurs every N web documents fetched (BSFSN strategy).
Small-scale experiments attest that HCLA allows to overcome the limitations of the initial training data while maintaining a high recall/precision ratio. Evaluation has been done on WebKB and Cora datasets comparing HCLA against well-known methods such as BRFS, BackLink count (BL), Shark Search (SS1 & SS2) and PageRank (PR).

Related research in the lab also includes methods such as Probabilistic Latent Semantic Indexing (PLSI) for both text and web retrieval (PHITS). A novel incremental updating scheme for PLSI (Recursive PLSI, RPLSI) has been developed. Its main benefits are:
- It does not require to train the model from the beginning
- It updates not only the probabilities of the new-document as folding-in does, but also all the probabilities of terms and documents
First experimental results are promising - RPLSI is attested to have lower mean square error than PLSI folding-in.
Relevant Publications
G. Almpanidis and C. Kotropoulos, "Combined text and link analysis for focused crawling", in Proc. Int. Conf. Advances in Pattern Recognition (ICAPR 2005), vol. LNCS 3686, part I, pp. 278-287, Bath, U.K., August, 2005.
G. Almpanidis, C. Kotropoulos and I. Pitas, "Focused crawling using latent semantic indexing- An application for vertical search engines", in Proc. 2005 European Conf. Digital Libraries (ECDL 2005), vol. LNCS 3652, pp. 402-413, Vienna, September, 2005.
G. Almpanidis, C. Kotropoulos, and I. Pitas, "Combining Text and Link Analysis for Focused Crawling - An Application for Vertical Search Engines", Information Systems, accepted for publication.
C. Kotropoulos and A. Papaioannou, "A novel-updating scheme for probabilistic latent semantic indexing", in Proc. 4th Panhellenic Artificial Intelligence Conf. (SETN-06), vol. LNAI 3966, pp. 137-147, Heraklion, Greece, May 19-20, 2006.
Research Projects
Herakleitos - (Operational programme for Education and Initial Vocational Training - 3rd Community Support Framework): Processing of Multimedia Signals.
Cluster analysis (or Clustering), which is widely used in many computer science areas, such as data mining, information retrieval, machine learning and image segmentation, studies algorithms and methods for grouping or classifying ”similar” objects into clusters. The notion of ”similarity” varies depending on the purpose of the study, the domain-specific assumptions and the prior knowledge of the problem. The objects (individuals, cases, or subjects) which comprise the raw data in cluster analysis are described either by a set of measurements or by relationships between them.
The unsupervised clustering methods are classified into:
- Partitional: the data set is directly decomposed into a set of disjoint clusters that iteratively optimize a certain criterion function
- Hierarchical: produces a nested sequence of partitions resulting in a tree of clusters (dendrogram) which show the inter-relationship between clusters.
Word Clustering aims to produce groups of words with similar characteristics, such as meaning, syntactical and grammatical information.
Our Method
Several hierarchical clustering algorithms have been implemented and applied in the field of word clustering:
- Single-link
- Complete-link
- Minimization of the loss of the mutual information, which corresponds to the information carried on a particular word when prior information is known. Prior information is captured by using the appropriate statistical language models:
- Bigrams (or Trigrams): the current word is predicted based on one (or two) immediate preceding words
- Long-Distanced Bigrams met in different distances and interpolated either over the component probabilities of the models or over the full models. It serves in capturing long distance dependencies with a small number of free parameters.
The use of Long-Distanced Bigrams models in word clustering by minimizing the loss of mutual information comprises our novelty together with an improvement of the clustering algorithm in using robust estimates for the mean and covariance matrix.
Representative experimental results have been conducted on a subset of the Reuters corpus collection.
Cluster validity assessment have been performed by using:
- external indices: Rand, Jaccard
- measurements based on mutual information: entropy, average mutual information, normalized avergae mutual information and variation of information
while the performance of the language models employed have been tested by means of perplexity.

Downloads
-
Relevant Publications
N. Bassiou and C. Kotropoulos, "Interpolated Distanced Bigram Language Models for Robust Word Clustering", in Proc. of IEEE Int. Workshop on Nonlinear Signal and Image Processing (NSIP 2005) , Sapporo, Japan, 18-20 May, 2005.
N. Bassiou, C. Kotropoulos and I. Pitas, "Hierarchical word clustering for relevance judgements in information retrieval", in Proc. of Workshop on Pattern Recognition in Information Systems (PRIS'01), pp. 139-148, Setubal, Portugal, 6-7 July, 2001.
Research Projects
MUSCLE - “Multimedia Understanding through Semantics, Computation and LEarning” (FP6-507752)